Disclosure: The automation pipeline described in this article is the same system that powers ByteWire.press. A production-ready version of the n8n workflow is available as OmniWire for those who’d rather skip the build phase.
There’s a quiet revolution happening in content creation. While most people are still copying and pasting ChatGPT outputs into their blogs, a handful of builders are designing fully autonomous content systems — pipelines where AI doesn’t just write, but researches, fact-checks, generates images, optimizes for search, and publishes — all without a human in the loop.
The technology behind this? It’s not some expensive enterprise platform. It’s n8n, an open-source workflow automation tool, combined with modern AI models like Google’s Gemini. And the results are surprisingly good.
In this article, we’ll break down how automated AI content pipelines actually work, why they’re more reliable than you’d expect, and what it takes to build one.
Why Single-Prompt AI Content Falls Short
If you’ve ever asked ChatGPT to “write an article about X,” you know the result: a generic, surface-level piece that reads like every other AI article on the internet. No original research. No verified facts. No real perspective.
That’s because asking one AI model to do everything — research, write, optimize, format — is like asking one person to be the reporter, editor, fact-checker, photographer, and web developer simultaneously. The output suffers at every level.
The solution isn’t a better prompt. It’s a better system.
The Multi-Agent Approach: How Real AI Pipelines Work
The concept is borrowed from how actual newsrooms operate. Instead of one person doing everything, you have specialists — each handling one part of the process, each optimized for their specific job.
In an AI content pipeline, this translates to multiple specialized agents working in sequence:
An Editor agent scans incoming stories and selects the ones worth covering — looking for unique angles rather than just the biggest headlines.
A Research agent uses live web search to gather facts, context, and supporting data about the selected topic.
A Writer agent crafts the article from scratch, using only the verified research — not its own training data.
A Fact-Checking agent goes through every claim in the finished article and verifies it against live sources.
An SEO agent handles metadata — titles, descriptions, keywords — without touching the content itself.
A Quality Review agent runs a final check on structure, formatting, and completeness.
Each agent has a single job. Each one is prompted differently, uses different model settings, and passes its output to the next stage. If any agent flags an issue, the pipeline handles it — rewrites, corrections, or rejection — automatically.
n8n: The Engine Behind the Automation
n8n is an open-source workflow automation platform — think Zapier, but self-hosted, far more flexible, and free. It gives you a visual canvas where you connect nodes (triggers, API calls, code blocks, conditional logic) into complex workflows.
For AI content pipelines, n8n is ideal because:
You control the entire flow. Every API call, every conditional branch, every retry mechanism is visible and editable.
It runs on your own server. No vendor lock-in, no monthly SaaS fees, no data leaving your infrastructure.
You can call any AI model. Gemini, GPT, Claude, Llama — any API that accepts HTTP requests works.
Code nodes let you add custom logic. Deduplication, content parsing, image processing — anything JavaScript can do.
A production-grade content pipeline typically runs 50-80+ nodes. That sounds complex, but each node does one small, clear thing — and n8n’s visual editor makes the flow intuitive to follow.
Fact-Checking: The Part Nobody Talks About
Here’s the problem everyone in the AI content space is quietly ignoring: language models hallucinate. They confidently state statistics that don’t exist, attribute quotes to the wrong people, and mix up dates, prices, and product names.
For a blog post about “10 productivity tips,” nobody notices. But for a news site covering real events, companies, and technologies? A single fabricated detail destroys credibility.
This is where the multi-agent approach earns its keep. A dedicated Fact-Checking agent — equipped with live Google Search — can verify every claim in the article against current sources. Not just the headline facts, but the supporting details: the funding amount, the launch date, the CEO’s name, the specific feature that was announced.
When issues are found, a Fact Fixer agent corrects them using the verified sources. Articles with unfixable problems get rejected entirely. They never reach your site.
It’s not perfect — no system is. But it catches the vast majority of hallucinations that would otherwise slip through unnoticed.
AI-Generated Images: Better Than Stock Photos
Every article needs visuals. Stock photos are generic, expensive, and often irrelevant. AI image generation has gotten good enough to produce custom, contextually relevant images for every article.
In a well-designed pipeline, the Writer agent specifies what each image should depict (based on the article’s content), and image generation models create them on demand. The images get automatically optimized as WebP, uploaded to the media library, and placed within the article where they contextually belong.
Three unique images per article — a hero and two inline visuals — at a fraction of the cost of hiring an illustrator or licensing stock photography.
The Deduplication Problem (And How to Solve It)
When you’re pulling from multiple RSS feeds, the same story shows up from different sources with different headlines. “Apple Announces New iPhone” from TechCrunch and “Here’s Everything in Apple’s iPhone Launch” from The Verge — same story, different words.
Without smart deduplication, your pipeline publishes near-identical articles on the same topic. It’s the fastest way to make a site look like spam.
The solution is layered detection:
Keyword overlap — simple but catches the obvious duplicates.
Semantic AI comparison — catches stories that share no keywords but cover the same event.
Embedding similarity — mathematical comparison using vector representations of each article.
Editor awareness — the AI editor sees all recently published titles and avoids selecting already-covered topics.
Each layer catches what the others miss. Combined, they’re remarkably effective at ensuring every published article covers something genuinely new.
What the Output Actually Looks Like
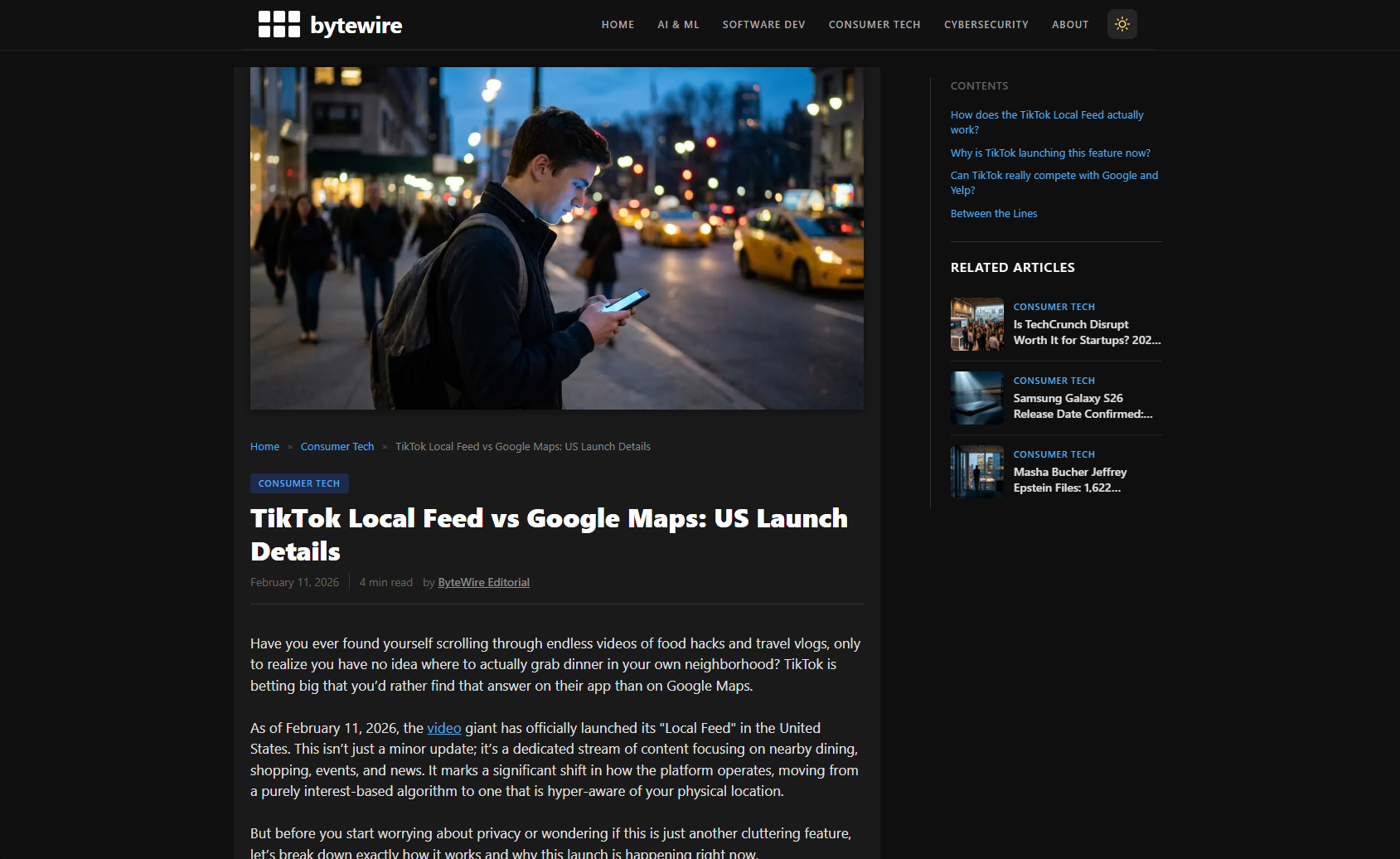
If you’re curious what a fully automated AI news site looks like in practice, take a look at ByteWire.press. Every article on the site — from the writing to the images to the SEO metadata — was produced entirely by an automated multi-agent pipeline running on n8n.
Browse a few articles. The writing has genuine perspective (not the “in today’s rapidly evolving landscape” AI slop). The facts check out. The images are relevant. The SEO structure is solid. It’s not indistinguishable from human-written content, but it’s far closer than most people expect.
The Real Costs
Running a pipeline like this isn’t free, but it’s dramatically cheaper than the alternative:
VPS hosting: $10-15/month for a server that handles everything.
AI API usage: $60-150/month for Gemini API calls (text generation + image generation + embeddings).
n8n: Free (self-hosted, open source).
WordPress: Free.
For roughly $100/month total, you get a system that produces 10-15 original, fact-checked, SEO-optimized articles per day. Compare that to hiring freelance writers at $50-200 per article. The math speaks for itself.
Is This the Future of Content?
Not all content. But for certain categories — news aggregation, product roundups, market analysis, tech coverage — automated pipelines are already producing content that competes with (and sometimes outperforms) human-written alternatives.
The advantage isn’t just cost. It’s consistency. A pipeline doesn’t have writer’s block. It doesn’t miss deadlines. It doesn’t produce varying quality depending on who’s available. It publishes every day, on schedule, at a consistent quality bar.
The people building these systems today are positioning themselves for a world where content is abundant and distribution is everything. The competitive advantage isn’t writing more — it’s writing smarter, faster, and more reliably than everyone else.
If you’re interested in building something like this yourself, the learning curve is real but manageable — n8n’s documentation is solid, and the Gemini API is straightforward to work with. Start small (a 10-node proof of concept), get comfortable with the patterns, and scale up from there.