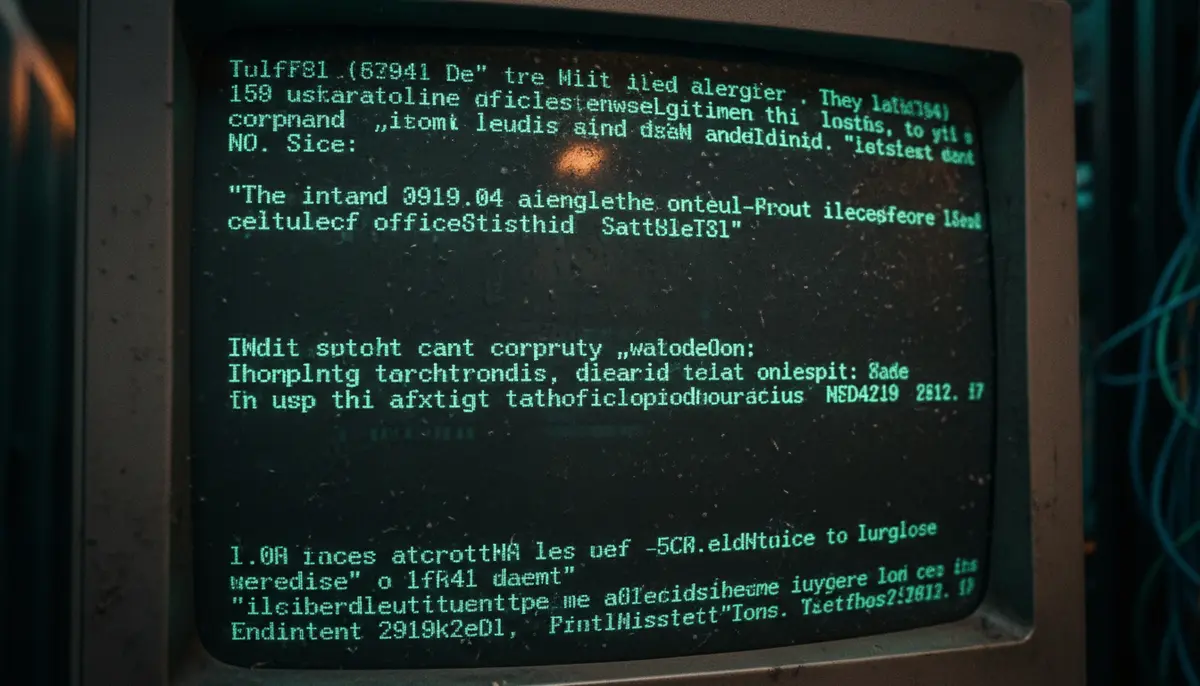
If you have spent any time scrolling through the recently released Department of Justice documents regarding the Jeffrey Epstein investigation, you might have paused at some of the emails. They look bizarre. Sentences are chopped up. Random equals signs (=) appear at the ends of lines. Common punctuation is replaced by strings like "=20" or "=3D."
Naturally, the internet did what the internet does best: it started looking for patterns. Conspiracy theories sprouted almost immediately, suggesting that this garbled text was a sophisticated cipher used by a cabal of elites to communicate in secret. It is a compelling narrative, especially given the dark nature of the subject matter.
But as a senior tech journalist who has watched digital standards evolve for over a decade, I can tell you the reality is far less thrilling and far more technical. It isn’t a secret language. It is a massive administrative error. What you are seeing is the digital equivalent of a photocopier jam from the 1990s.
What are those strange equals signs in the text?
To understand why these emails look like a math homework assignment gone wrong, we have to go back to the early days of the internet. The specific glitch visible in these documents is known as Quoted-Printable encoding.
When email protocols were first developed, systems were designed to handle ASCII text, which is a 7-bit format. Basically, early email servers were very picky and could only process basic English letters and numbers. If you tried to send 8-bit data—like a modern file attachment or even certain special characters—through those old 7-bit pipes, the system would break.
Quoted-Printable encoding was the workaround. It translates unsafe characters into safe ASCII sequences using the equals sign as an escape character. For example, "=20" is the code for a space, and "=3D" represents an actual equals sign. The ubiquitous "=" you see at the end of lines is a "soft line break," used to split long strings of text so they fit within the historical 76-character limit for email transmission.
According to experts like Lars Ingebrigtsen, the mess we are seeing in the Epstein files is likely a combination of "buggy continuation line decoding" and issues with handling non-ASCII characters. It is not a code; it is the raw plumbing of the internet exposed because someone forgot to put the floorboards back down.
How did the Department of Justice mess this up?
You might be wondering how a federal agency releases documents that look like raw code. The answer lies in a flawed workflow. The emails were likely stored in their raw MIME (Multipurpose Internet Mail Extensions) format. When the time came to release them to the public, the DOJ staff needed to convert them into PDFs.
According to Chris Prom, a professor and archivist at the University of Illinois, the glyphs are "probably some artifact of a poor conversion process." Instead of using software that properly renders the email (interpreting the code and displaying the intended text), the DOJ likely used a tool that simply printed the raw text file directly to a PDF.
It is the digital equivalent of printing out the HTML source code of a website instead of the webpage itself. As Mahmoud Al-Qudsi of NeoSmart Technologies noted regarding the incident, "The unlucky intern that was assigned to the documents in question didn’t realize the significance of what they were looking at."
Is there a security risk hidden in the glitch?
While the garbled text is annoying to read, the incompetence behind it actually led to a much more severe security failure. It wasn’t just text encoding that got exposed; researchers found that the DOJ’s "lazy" PDF conversion process also included raw Base64 strings.
Base64 is another encoding scheme used to turn binary data (like images or zip files) into text so it can be sent via email. Because the DOJ failed to render the emails properly, they inadvertently included the raw code for the attachments inside the PDF files.
Tech-savvy users were able to take those strings of text, reverse-engineer them, and reconstruct the original, unredacted files. This allowed them to bypass redaction efforts entirely, viewing sensitive images and even passwords that were meant to be hidden. This goes beyond a formatting error; it is a fundamental failure of digital forensics standards.
Why It Matters
This incident is a stark reminder of the widening gap between government bureaucracy and modern technical competency. While the conspiracy theories about "secret codes" distract the public, the real story is that the Department of Justice lacks the basic digital literacy required for secure e-discovery and data redaction. This was not a malicious leak, but it was a negligent one. If federal agencies cannot distinguish between raw MIME data and a renderable document, we have to question their ability to handle truly sensitive cybersecurity threats in the future. The ultimate losers here are not just the subjects of the investigation, but the public trust in the government’s ability to manage its own digital archives.